Recently I was involved in a professional services engagement along side Google Professional Services. In that engagement I got to see first hand how Google implements solutions on GCP, including the deployment of a high-performance compute platform proof of concept. One of the most interesting aspects of that engagement was how the Google team implemented the entire solution using the Infrastructure as Code IaC) paradigm. At no point in the development of the POC did the team configure something directly in the console. This allowed them to build and tear-down the environment as needed, and once complete, they could turn over a running POC to the customer for further development and implementation. So taking direction from how Google does things, I decided to do the same for the Ansible host configuration in the previous post.
My goal was to automate the implementation of the Ansible host using GCP Deployment manager so that in the future when I want to run Ansible tests, I can deploy the environment within 10 minutes and remove it instantly when I am done. To keep the entire environment ephemeral, all of the configuration was put into GitHub. Future Ansible playbooks will also be placed in GitHub so that all I need to do is spin up the environment, clone the latest playbook I am working on and continue where I left off.
You can see the full configuration on GitHub here:
In building the configuration I relied on the code that the Google PS team used as an example along with other examples from the Google documentation and from StackOverflow. Some of the python scripting is my own since it is fairly basic and unique to this project.
For this project, I set out to learn Ansible and how it could be used to automate network configurations on Google Cloud Platform (GCP). Since may enterprises are pushing their engineering and operations teams to use Ansible to automate their manual tasks, I also figured that this would be an opportunity for me to gain a deeper understanding for the potential of what this type initiative might be able to achieve. Finally, by implementing the automation on GCP, I felt that this exercise would give me the opportunity to further practice what I had learned while getting my Google Architect certification. What follows is a description of the environment I setup and some of the insights I gained in the process.
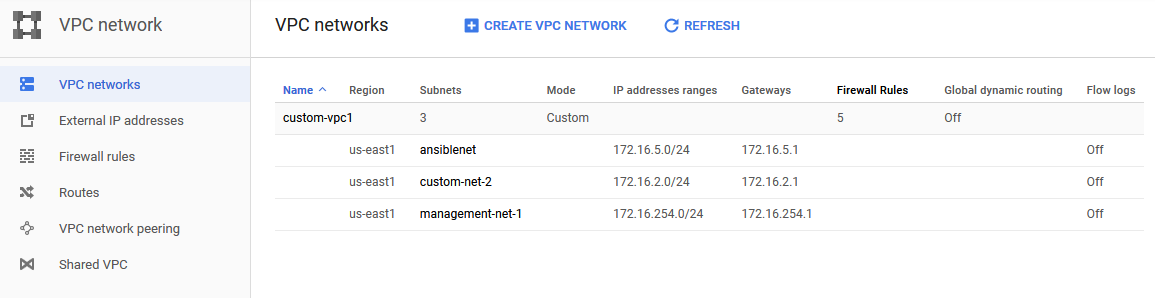
Since my goal was not to become a guru in developing Ansible playbooks, I reused and modified some sample playbooks provided by Ansible in their documentation. For the testing I setup an Ubuntu 18.04LTE host running Ansible 2.7 on a GCP g1-small (1 CPU, 1.7G RAM) instance in a dedicated management subnet. The diagram below shows the final configuration I was trying to achieve.
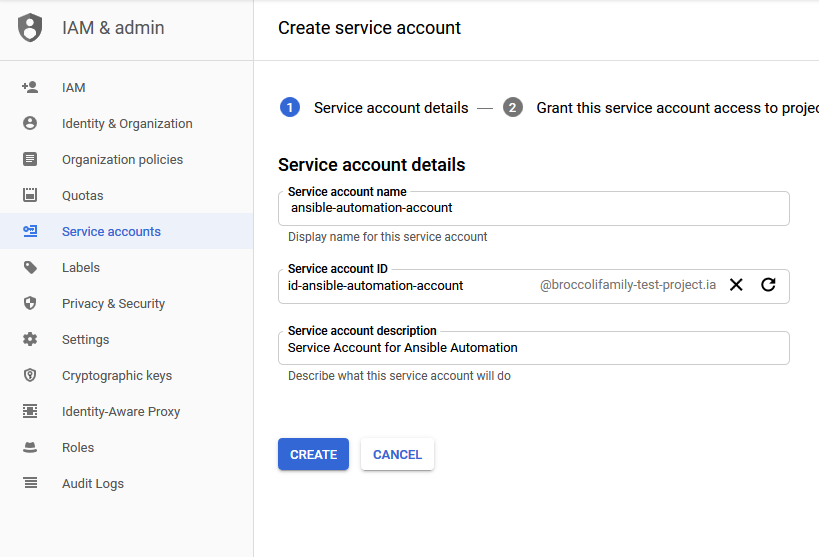
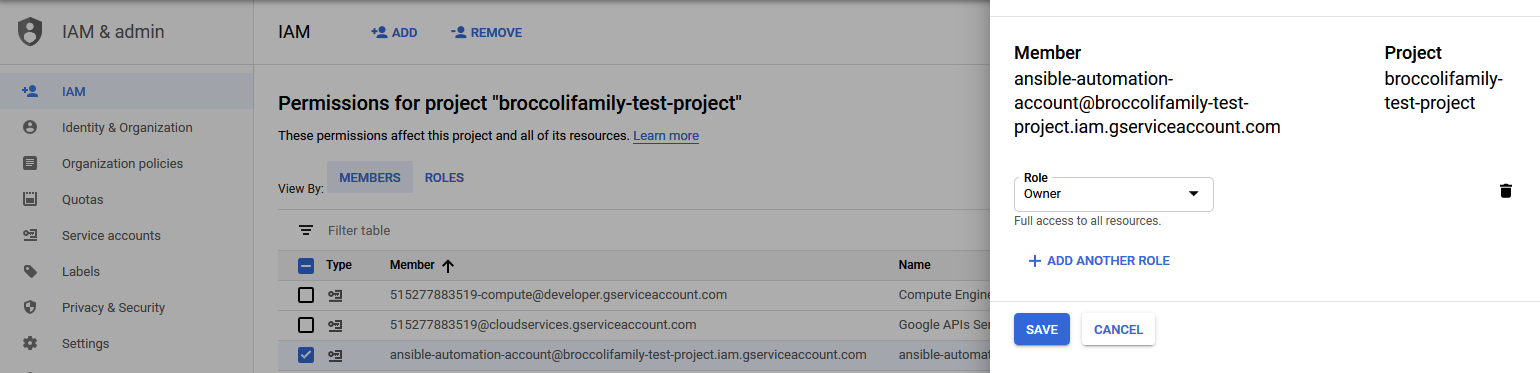
The first step in the process is to create a service account in GCP to allow Ansible to access the environment.
Although I gave the service account full owner rights to the project so that I would not be struggling with access rights, in a production environment, limiting the rights of the service account to only the rights needed to execute approved playbooks should be considered so that the danger of unsanctioned changes being performed are minimized.
The service account credentials were downloaded to the Ansible host so that it can be used when executing commands.
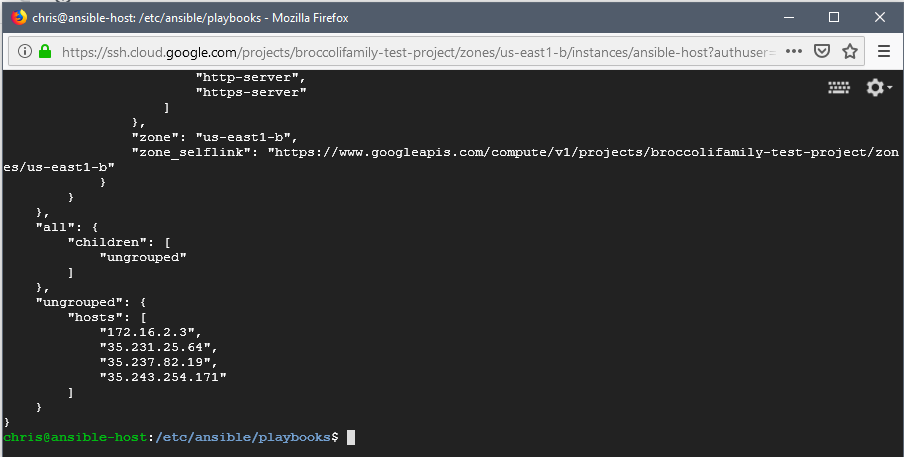
The next step was to enable Ansible to query the target system for the current configuration. After all, you cannot change something you know nothing about. This is done my means of an inventory file which instructs Ansible how to execute the API call to collect the inventory dynamically from GCP.
The output is a JSON file showing the complete configuration of your GCP environment.
At this point the environment is ready to begin running playbooks. As mentioned above, I relied on examples from the Ansible documentation for my testing. In this case I copied an example playbook which adds a subnet to GCP and modified it based on my environment. I also played around with different variable configurations to see the effect of each on the execution. The playbook I ran is shown below.
The output below shows that the execution was successful, and a new subnet named ‘ansiblenet’ was created.
Note that in the output from running the playbook shows changed=0 because I had already run the playbook and there was nothing to change. This demonstrates one of the key design goals of Ansible called idempotence, which stipulates that running a playbook multiple times will not change the environment beyond the initial intention of the playbook (in this case adding a new subnet called ansiblenet). This can be beneficial in situations where a playbook fails to complete and needs to be re-run, but on only the portions which were unsuccessful.
Another thing I ran into is that if you also try and create a new network, you end up with a legacy network instead of a VPC (the playbook will create the network but fail on the subnet because subnets aren’t supported on legacy networks). There is no updated version of the gcp_compute_network module which can create a custom VPC. So for now a VPC must be created manually and just referenced here. As long as it is present, you can add subnets to it using this playbook.
All in all I think I achieved what I set out to do. The ease at which I was able to come up to speed and perform a simple automation indicates that the initiative to use Ansible as a global tool is a reasonable goal and should provide benefits with minimal cost and effort. Of course, to be able to develop my own playbooks from scratch will require much more time and testing, something I’ll save for another cold weekend, unless something new comes along.
Once I had a working Instance Group I was able to then able to begin configuring the load balancer. IPv6 load balancing is described in this article. Essentially they are configuring a reverse proxy which terminates the IPv6 connection and builds a new IPv4 connection to the backend server.
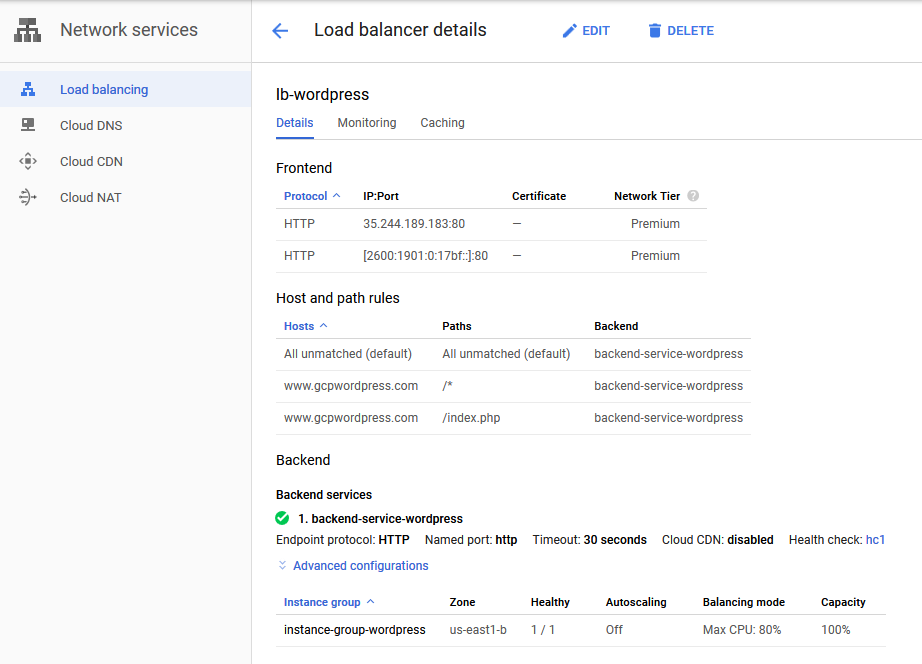
The first step is to select a load balancer and in this case I selected an HTTP(S) load balancer. Once selected you need to configure the Backend, the Path Rules/URL Map and the Frontend as shown in the following diagram:
Load Balancer Configuration
The Back End maps the load balancer to the instance group. I chose to disable autoscaling and limit the total number of hosts to 1. If you have a stateless server you can allow the load balancer to autoscale the service as needed based on load. Since my LAMP server has a local MySQL database this would not work.
For the Path Rules I added the name and pointed it to the main page for WordPress. You need to enter a name for the server since GCP does not take IPv6 IP addresses (IPv4 works fine). Without this rule the load balancer will not know where to route the incoming http packet.
For the Front End I added both IPv4 and IPv6 addresses for testing purposes, in case I needed IPv4 access.
Once that was complete I could begin testing. Luckily for me my ISP has already rolled out IPv6 to my house so I already had IPv6 access. For the client configuration, I added a new static entry in my hosts file to allow me to use a name to access the server. I only configured the IPv6 address and to make sure IPv4 was not used at any point in the connection, I removed IPv4 from my network adapter. Once this was done, I was able to use my web browser and access the WordPress host.
Adapter Congiruation
In Wireshark you can see the entire IPv6 connection which shows clearly that the configuration works.